Bussiness
Improve productivity when processing scanned PDFs using Amazon Q Business | Amazon Web Services

Amazon Q Business is a generative AI-powered assistant that can answer questions, provide summaries, generate content, and extract insights directly from the content in digital as well as scanned PDF documents in your enterprise data sources without needing to extract the text first.
Customers across industries such as finance, insurance, healthcare life sciences, and more need to derive insights from various document types, such as receipts, healthcare plans, or tax statements, which are frequently in scanned PDF format. These document types often have a semi-structured or unstructured format, which requires processing to extract text before indexing with Amazon Q Business.
The launch of scanned PDF document support with Amazon Q Business can help you seamlessly process a variety of multi-modal document types through the AWS Management Console and APIs, across all supported Amazon Q Business AWS Regions. You can ingest documents, including scanned PDFs, from your data sources using supported connectors, index them, and then use the documents to answer questions, provide summaries, and generate content securely and accurately from your enterprise systems. This feature eliminates the development effort required to extract text from scanned PDF documents outside of Amazon Q Business, and improves the document processing pipeline for building your generative artificial intelligence (AI) assistant with Amazon Q Business.
In this post, we show how to asynchronously index and run real-time queries with scanned PDF documents using Amazon Q Business.
Solution overview
You can use Amazon Q Business for scanned PDF documents from the console, AWS SDKs, or AWS Command Line Interface (AWS CLI).
Amazon Q Business provides a versatile suite of data connectors that can integrate with a wide range of enterprise data sources, empowering you to develop generative AI solutions with minimal setup and configuration. To learn more, visit Amazon Q Business, now generally available, helps boost workforce productivity with generative AI.
After your Amazon Q Business application is ready to use, you can directly upload the scanned PDFs into an Amazon Q Business index using either the console or the APIs. Amazon Q Business offers multiple data source connectors that can integrate and synchronize data from multiple data repositories into single index. For this post, we demonstrate two scenarios to use documents: one with the direct document upload option, and another using the Amazon Simple Storage Service (Amazon S3) connector. If you need to ingest documents from other data sources, refer to Supported connectors for details on connecting additional data sources.
Index the documents
In this post, we use three scanned PDF documents as examples: an invoice, a health plan summary, and an employment verification form, along with some text documents.
The first step is to index these documents. Complete the following steps to index documents using the direct upload feature of Amazon Q Business. For this example, we upload the scanned PDFs.
- On the Amazon Q Business console, choose Applications in the navigation pane and open your application.
- Choose Add data source.
- Choose Upload Files.
- Upload the scanned PDF files.
You can monitor the uploaded files on the Data sources tab. The Upload status changes from Received to Processing to Indexed or Updated, as which point the file has been successfully indexed into the Amazon Q Business data store. The following screenshot shows the successfully indexed PDFs.
The following steps demonstrate how to integrate and synchronize documents using an Amazon S3 connector with Amazon Q Business. For this example, we index the text documents.
- On the Amazon Q Business console, choose Applications in the navigation pane and open your application.
- Choose Add data source.
- Choose Amazon S3 for the connector.
- Enter the information for Name, VPC and security group settings, IAM role, and Sync mode.
- To finish connecting your data source to Amazon Q Business, choose Add data source.
- In the Data source details section of your connector details page, choose Sync now to allow Amazon Q Business to begin syncing (crawling and ingesting) data from your data source.
When the sync job is complete, your data source is ready to use. The following screenshot shows all five documents (scanned and digital PDFs, and text files) are successfully indexed.

The following screenshot shows a comprehensive view of the two data sources: the directly uploaded documents and the documents ingested through the Amazon S3 connector.

Now let’s run some queries with Amazon Q Business on our data sources.
Queries on dense, unstructured, scanned PDF documents
Your documents might be dense, unstructured, scanned PDF document types. Amazon Q Business can identify and extract the most salient information-dense text from it. In this example, we use the multi-page health plan summary PDF we indexed earlier. The following screenshot shows an example page.

This is an example of a health plan summary document.
In the Amazon Q Business web UI, we ask “What is the annual total out-of-pocket maximum, mentioned in the health plan summary?”
Amazon Q Business searches the indexed document, retrieves the relevant information, and generates an answer while citing the source for its information. The following screenshot shows the sample output.

Queries on structured, tabular, scanned PDF documents
Documents might also contain structured data elements in tabular format. Amazon Q Business can automatically identify, extract, and linearize structured data from scanned PDFs to accurately resolve any user queries. In the following example, we use the invoice PDF we indexed earlier. The following screenshot shows an example.
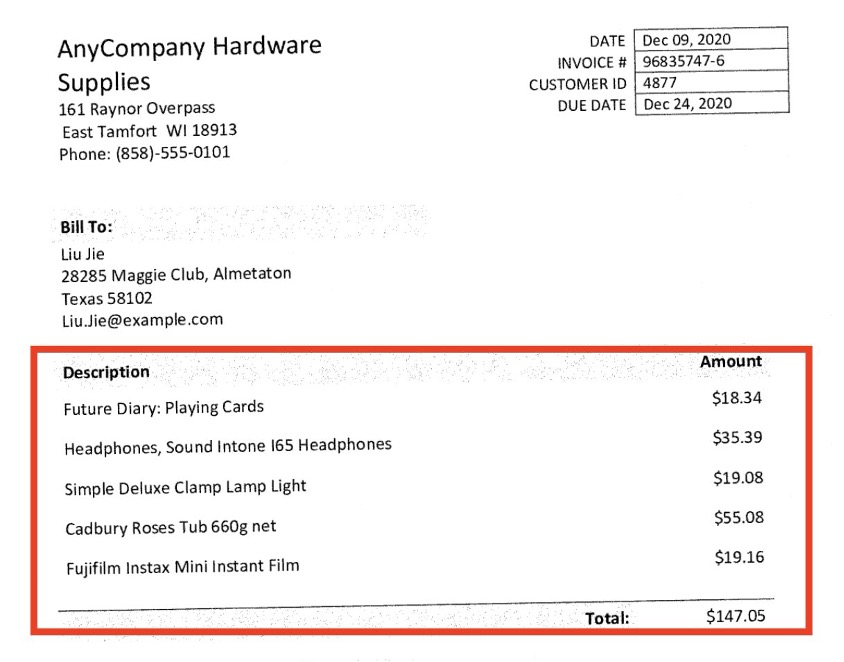
This is an example of an invoice.
In the Amazon Q Business web UI, we ask “How much were the headphones charged in the invoice?”
Amazon Q Business searches the indexed document and retrieves the answer with reference to the source document. The following screenshot shows that Amazon Q Business is able to extract bill information from the invoice.

Queries on semi-structured forms
Your documents might also contain semi-structured data elements in a form, such as key-value pairs. Amazon Q Business can accurately satisfy queries related to these data elements by extracting specific fields or attributes that are meaningful for the queries. In this example, we use the employment verification PDF. The following screenshot shows an example.

This is an example of an employment verification form.
In the Amazon Q Business web UI, we ask “What is the applicant’s date of employment in the employment verification form?” Amazon Q Business searches the indexed employment verification document and retrieves the answer with reference to the source document.

Index documents using the AWS CLI
In this section, we show you how to use the AWS CLI to ingest structured and unstructured documents stored in an S3 bucket into an Amazon Q Business index. You can quickly retrieve detailed information about your documents, including their statuses and any errors occurred during indexing. If you’re an existing Amazon Q Business user and have indexed documents in various formats, such as scanned PDFs and other supported types, and you now want to reindex the scanned documents, complete the following steps:
- Check the status of each document to filter failed documents according to the status
"DOCUMENT_FAILED_TO_INDEX". You can filter the documents based on this error message:
"errorMessage": "Document cannot be indexed since it contains no text to index and search on. Document must contain some text."
If you’re a new user and haven’t indexed any documents, you can skip this step.
The following is an example of using the ListDocuments API to filter documents with a specific status and their error messages:
The following screenshot shows the AWS CLI output with a list of failed documents with error messages.

Now you batch-process the documents. Amazon Q Business supports adding one or more documents to an Amazon Q Business index.
- Use the BatchPutDocument API to ingest multiple scanned documents stored in an S3 bucket into the index:
The following screenshot shows the AWS CLI output. You should see failed documents as an empty list.

- Finally, use the ListDocuments API again to review if all documents were indexed properly:
The following screenshot shows that the documents are indexed in the data source.

Clean up
If you created a new Amazon Q Business application and don’t plan to use it further, unsubscribe and remove assigned users from the application and delete it so that your AWS account doesn’t accumulate costs. Moreover, if you don’t need to use the indexed data sources further, refer to Managing Amazon Q Business data sources for instructions to delete your indexed data sources.
Conclusion
This post demonstrated the support for scanned PDF document types with Amazon Q Business. We highlighted the steps to sync, index, and query supported document types—now including scanned PDF documents—using generative AI with Amazon Q Business. We also showed examples of queries on structured, unstructured, or semi-structured multi-modal scanned documents using the Amazon Q Business web UI and AWS CLI.
To learn more about this feature, refer to Supported document formats in Amazon Q Business. Give it a try on the Amazon Q Business console today! For more information, visit Amazon Q Business and the Amazon Q Business User Guide. You can send feedback to AWS re:Post for Amazon Q or through your usual AWS support contacts.
About the Authors
 Sonali Sahu is leading the Generative AI Specialist Solutions Architecture team in AWS. She is an author, thought leader, and passionate technologist. Her core area of focus is AI and ML, and she frequently speaks at AI and ML conferences and meetups around the world. She has both breadth and depth of experience in technology and the technology industry, with industry expertise in healthcare, the financial sector, and insurance.
Sonali Sahu is leading the Generative AI Specialist Solutions Architecture team in AWS. She is an author, thought leader, and passionate technologist. Her core area of focus is AI and ML, and she frequently speaks at AI and ML conferences and meetups around the world. She has both breadth and depth of experience in technology and the technology industry, with industry expertise in healthcare, the financial sector, and insurance.
 Chinmayee Rane is a Generative AI Specialist Solutions Architect at AWS. She is passionate about applied mathematics and machine learning. She focuses on designing intelligent document processing and generative AI solutions for AWS customers. Outside of work, she enjoys salsa and bachata dancing.
Chinmayee Rane is a Generative AI Specialist Solutions Architect at AWS. She is passionate about applied mathematics and machine learning. She focuses on designing intelligent document processing and generative AI solutions for AWS customers. Outside of work, she enjoys salsa and bachata dancing.
 Himesh Kumar is a seasoned Senior Software Engineer, currently working at Amazon Q Business in AWS. He is passionate about building distributed systems in the generative AI/ML space. His expertise extends to develop scalable and efficient systems, ensuring high availability, performance, and reliability. Beyond the technical skills, he is dedicated to continuous learning and staying at the forefront of technological advancements in AI and machine learning.
Himesh Kumar is a seasoned Senior Software Engineer, currently working at Amazon Q Business in AWS. He is passionate about building distributed systems in the generative AI/ML space. His expertise extends to develop scalable and efficient systems, ensuring high availability, performance, and reliability. Beyond the technical skills, he is dedicated to continuous learning and staying at the forefront of technological advancements in AI and machine learning.
 Qing Wei is a Senior Software Developer for Amazon Q Business team in AWS, and passionate about building modern applications using AWS technologies. He loves community-driven learning and sharing of technology especially for machine learning hosting and inference related topics. His main focus right now is on building serverless and event-driven architectures for RAG data ingestion.
Qing Wei is a Senior Software Developer for Amazon Q Business team in AWS, and passionate about building modern applications using AWS technologies. He loves community-driven learning and sharing of technology especially for machine learning hosting and inference related topics. His main focus right now is on building serverless and event-driven architectures for RAG data ingestion.

A survey found a Thanksgiving feast for 10 will run you $58. We went shopping in Jacksonville to find out if it’s true

Here’s what Pa Gov. learned from small businesses at a West Philly barbershop

Zhou Guanyu’s Emblematic Rise on the Formula 1 Fashion Scene

Germany: Bosch to cut 5,000 jobs with car industry in crisis – DW – 11/22/2024

This Four-Week Plan Will Help You Build Speed and Stamina

Black Friday DualSense deals have been cheaper but these PS5 discounts are better than nothing

What’s Next for Airbnb – Skift Travel Podcast

World Day of Remembrance 2024 – Bicycle Coalition of Greater Philadelphia

Bentley on Track to be the First Fair Trade-Certified U.S. Business University
