Tech
Phi-4: Microsoft’s Small AI Model Beats the Giants at Math

Microsoft just released Phi-4, its latest small language model, that surpasses even frontier models in math reasoning. In a technical report published on arxiv, Microsoft details how they use synthetic data and advanced post-training techniques to achieve superior performance on benchmarks.
Key Points:
- Phi-4 is a state-of-the-art small language model (14B parameters) optimized for complex reasoning and math.
- Phi-4 is currently available on Azure AI Foundry
- The model outperforms even larger counterparts on key benchmarks, proving the potential of smaller generative AI systems.
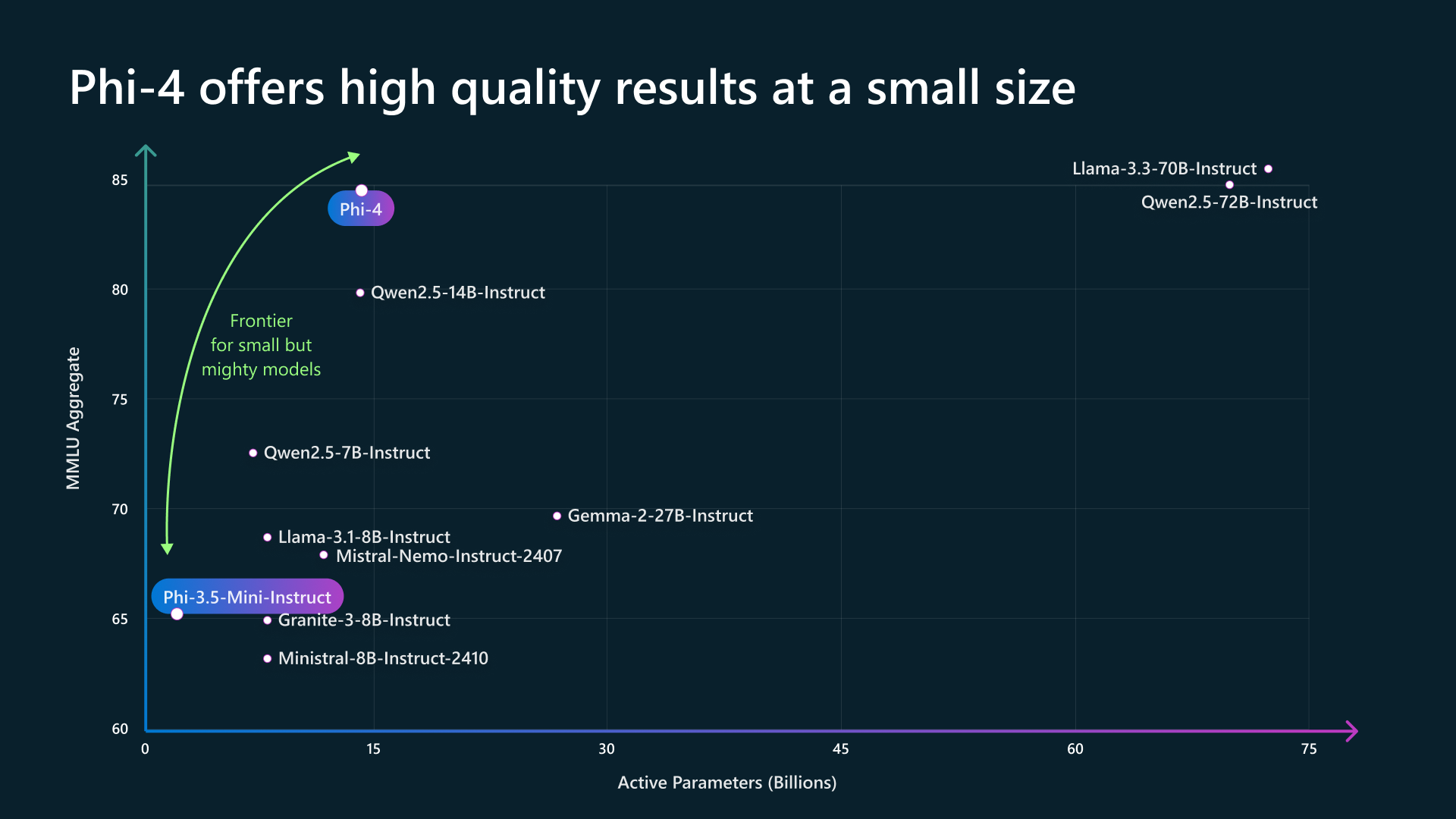
The breakthrough: Phi-4 represents a shift from the traditional “scale-first” mindset in AI. Instead of focusing on sheer size, Microsoft has honed its data and training processes to maximize performance per parameter. This approach allows Phi-4 to punch well above its weight, demonstrating that high-quality data and targeted training can eclipse brute computational power.
Its performance on many widely used reasoning-related benchmarks meets or exceeds that of Llama-3.1-405B. We find that Phi-4 significantly exceeds its teacher GPT-4o on the GPQA (graduate-level STEM Q&A).
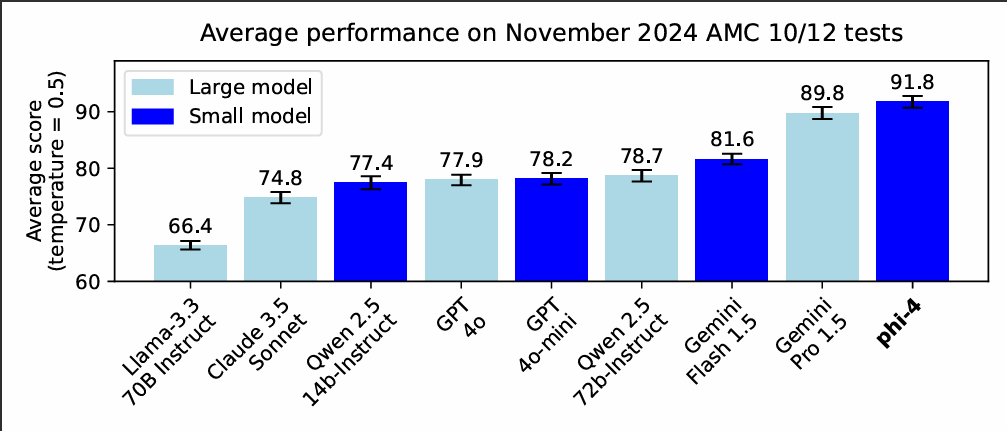
The model scored an unprecedented 91.8 points out of 150 on recent American Mathematics Competition (AMC) problems, surpassing Google’s flagship Gemini Pro 1.5, which scored 89.8 points.
The Reality Check: While Phi-4’s achievements are significant, benchmark performance must be interpreted with context. Microsoft’s technical report acknowledges several weaknesses, providing a balanced view of its capabilities:
- Factual Hallucinations: Phi-4 can fabricate plausible but incorrect information, such as inventing biographies for names that sound real. Without tools like search engines, such issues are challenging to fully resolve.
- Instruction Adherence: The model struggles with tasks requiring strict formatting or detailed instructions, such as tabular data generation or bullet-point structures. This limitation stems from its focus on Q&A and reasoning tasks during training.
- Reasoning Errors: Despite its prowess, Phi-4 can misstep in reasoning, occasionally misjudging even simple comparisons (e.g., incorrectly identifying “9.9” as smaller than “9.11”).
- Interaction Trade-offs: Phi-4 is optimized for single-turn queries, and as such sometimes provides overly detailed chain-of-thought explanations which can make simple interactions feel tedious.
Why It Still Matters: Despite these limitations, Phi-4 represents a major step forward in efficient AI design. Its ability to outperform larger models on STEM tasks while using fewer resources is a significant achievement.
The Bottom Line: Phi-4 exemplifies the promise of smaller, smarter models tailored for specific domains. While its performance on benchmarks like the AMC is remarkable, developers should consider its limitations, particularly in factual reliability and strict instruction adherence. Phi-4 is currently available on Azure AI Foundry and will be available on Hugging Face next week.

Do You Love Swimming? See 520 Swim Jobs You Might Love

Meta Reportedly Planning Displays For Ray-Ban Glasses Amid Push To Expand ‘AI-Native’ Devices
")
‘Blippi’ Games Launch on Lingokids App in New Deal With Moonbug Entertainment (EXCLUSIVE)

Santa Claus, the Fashion Icon

Working out on Christmas Eve? See if Planet Fitness, LA Fitness and other chains are open
Small businesses eligible for state funding assistance – Inside INdiana Business
AI will eavesdrop on world’s wildest places to track and help protect endangered wildlife

Monday expected to be busiest travel day of holiday season

Search through more than 13k jobs now listed in the Huntsville area – Hville Blast
