Tech
AMD Turns The Screws With “Turin” Server CPUs

If you are looking to upgrade your X86 server fleet – and there is lots of chatter about how many enterprises as well as hyperscalers and cloud builders are in the financial mood to do that – then the good news is that both Intel and AMD have now rolled out the best serial compute engines they have ever fielded.
For Intel, which still accounts for two-thirds of X86 server CPU shipments, the fact that it has drawn nearly even with AMD with a slight manufacturing process handicap is nothing short of amazing. For AMD, its performance and price advantages with the just-announced “Turin” Zen 5 and Zen 5c mean that AMD will continue to gain market share despite what Intel has been able to do to try to catch up in X86 server CPUs. And it probably means that sometime in the not too distant future, where there is process parity and performance parity, one of these two is going to blink first and start a price war.
But that day is not today. Right now, with the major hyperscalers working on their own Arm-based server CPU designs, both Intel and AMD are perfectly happy to compete with each other and pretend that the Arm wave is not happening. To do otherwise – meaning to actually charge less for X86 chips – is to leave a lot of revenue and all of the profits on the bargaining table, and neither company can afford to do that. And so, X86 server CPUs are a new legacy tier and homemade Arm chips are driving the price/performance curve lower. Someday, we think RISC-V will do this to Arm.
As usual, we will start our coverage of the Turin CPUs by getting you the basic feeds, speeds, and prices of the processors and then follow up with an architectural deep dive and then a competitive analysis from AMD’s perspective. (We were in the process of completing these stories for the Intel “Granite Rapids” Xeon 6 processors when Hurricane Helene had other ideas about what we would be doing.)
AMD has come a long way in its Epyc processor journey, and frankly it had to if it was ever going to regain credibility after essentially abandoning the datacenter in the early 2010s when its designs were up on the rocks and Intel came out strong with a revitalized 64-bit Xeon line that borrowed many ideas from AMD’s Opterons and did them better. This time around, it is Intel that has faltered, falling well behind AMD’s foundry partner Taiwan Semiconductor Manufacturing Co, and the delays in moving to advanced processes have cause Intel’s server CPU designers tremendous grief. There has been no way since 2019 for Intel to make “design wins” to compete and it has had to make do with “supply wins” because the company can still kick out the chips in a way that AMD would not.

Over the Epyc generations, the chiplet architecture has evolved and improved to the extent that an Epyc CPU comprised of nine, thirteen, or seventeen chiplets interconnected and dipped in organic substrate look and feel to software like a monolithic CPU of days gone by. And so, the Epyc chips have seen increasing adoption, particularly among the hyperscalers and cloud builders that like to cram as many cores as possible into a box to drive their guiding metric of price/performance per watt per unit of volume. (What we used to call SWaP back in the early 2000s, short for Space, Watts, and Performance.)
As the Epyc chiplet designs improved, adoption followed, and at this point in the Epyc line no one even questions for a second that AMD is in the server CPU game for the longest of hauls or that it cannot create a processor aimed at one-socket and two-socket servers that can stand toe to toe with anything anyone can put together, bar none.
But as we said, X86 processors will, we think, always cost more than homegrown Arm server chips among the hyperscalers and cloud builders because of all of the overhead that companies like Intel and AMD have to pay for with their product prices. Which is another way of saying that anyone who is not a hyperscaler or cloud builder is, by necessity, going to pay a high premium for server compute. It’s built in, unavoidable.
Most of the world is still running X86 applications on Windows Server that are not easily ported to Arm, so don’t get too nervous about it. But most new applications are written for Linux and not Windows Server and are relatively easily ported to Arm, so don’t get complacent, either. A steady state of anxiety seems to be a healthy attitude to take.
Given the current state of the X86 server market, we wonder just how high AMD’s market share can go.
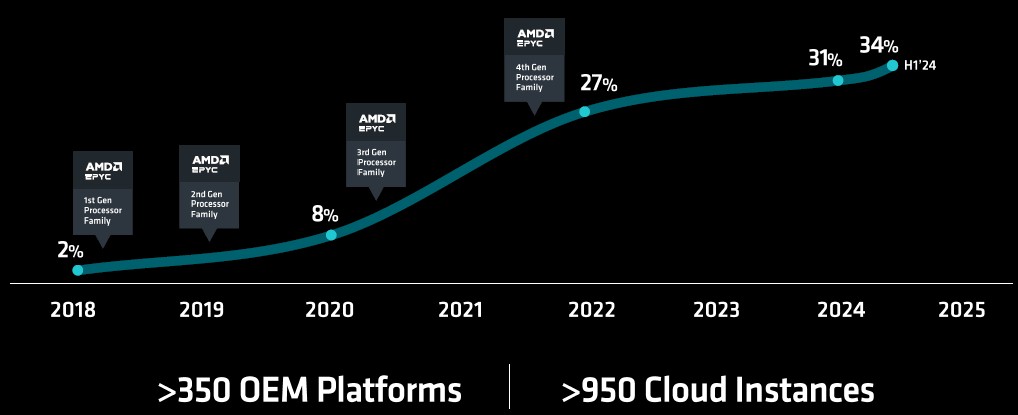
A lot depends on the dynamics inside of the hyperscalers and cloud builders, who represent more than half of server CPU shipments. If half of their fleets go to Arm and half stay X86 to support legacy X86 applications – in the long run, meaning Windows Server – then three-fourths of the market will still be X86 and that is an enormous target. But if hyperscalers and cloud builders start representing three-quarters of server CPU shipments and they only grow their X86 fleets organically to support Windows Server and some Linux workloads that customers prefer to have on X86 (for very sound reasons), then the pressure will be on Intel and AMD and the market shares could bob up and down depending on how aggressive either is in the price war. That assumes design and process parity, which is not a foregone conclusion, as we and Intel have learned.
There are plenty of microarchitectural changes in the Turin Zen 5 and Zen 5c cores, which drive integer instructions per clock (IPC) improvements up 17 percent compared to the Zen 4 and Zen 4c cores and which drive floating point IPC up by 37 percent.
Note: In our tables, when we calculate relative performance compared to our baseline four-core “Shanghai” Opteron 2387 processor running at 2.8 GHz, we only do that comparison for integer workloads, but at some point we will work backwards and add floating point relative performance.
This integer IPC improvement in the core design is consistent with the past leaps – 15 percent for “Rome” Epyc 7002s over “Naples” Epyc 7001s, 19 percent for Rome to “Milan” Epyc 7003s, and 14 percent for Milan to “Genoa” Epyc 9004s. The process shrinks, modifications to the L3 cache associated with each cores (the “c” cores have half the L3 cache at 2 MB compared to the plain vanilla cores which have 4 MB per core), and chiplet features and layouts let AMD dial up broadening SKU stacks. And this time around, AMD has a much broader stack with Turin, at 27 distinct chips, than Intel has with the combined Granite Rapids P-core and “Sierra Forest” E-core Xeon 6 line, which currently stands at a mere dozen SKUs.
This is not the Intel that we know, is it? How times have changed. Intel will be adding more low-end SKUs for both Granite Rapids and Sierra Forest in the first quarter of 2025, and AMD will probably add some telco and edge variants to Turin as well as 3D V-Cache Turin-X chips, so it may all even out.
The Turin chips represent an evolution over Genoa, and this is necessarily so given that the two chips have to plug into the same SP5 server socket. If you want to do anything big, you usually need a new socket, and server buyers and server designers want to get at least two generations out of a socket.
With the Turin chips, AMD is etching the cores in 3 nanometer processes from TSMC and the I/O and memory die in 4 nanometer processes, which is a sizable shrink from the 5 nanometer processes used for the Genoa cores and the 6 nanometer processes used for the Genoa I/O and memory die.
The table below gives you a feel for the changes over the five generations of products using the standard Zen cores, not the “c” variants:
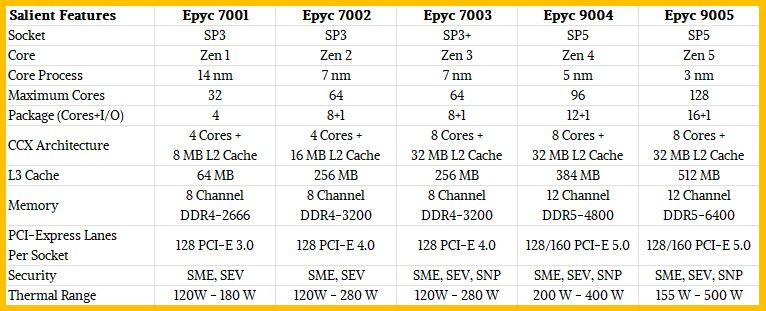
The core complex dies (CCDs) in the regular Turin products have eight cores and 32 MB of L2 cache shared across those cores, just like the Milan and Genoa designs. With the process shrinks on the core chiplets, from 7 nanometer with Milan to 5 nanometer with Genoa and 3 nanometer with Turin, AMD is able to cram 16 chiplets plus the I/O die into one package, and therefore has been able to double the top bin core count from 64 with Milan to 128 with Turin.
The L3 cache has increased proportionately to 512 MB with Turin, and the device has a dozen DDR5 memory channels just like Genoa. However, the Turin memory runs at 6.4 GHz, which is a 50 percent increase in speed and therefore represents a 50 percent increase in memory bandwidth per socket. This matches the 50 percent increase in core count compared to Genoa. The Genoa and Turin designs feature 128 or 160 lanes of PCI-Express 5.0 I/O, which is a condition imposed by the SP5 socket.
The two variants of Turin CPUs announced today don’t just have different cores, but they have different CCDs and different arrangements of CCDs to focus on different workloads in the datacenter.

The so-called “scale up” Turins based on the Zen 5 CCDs, shown on the left in the chart above, have sixteen CCDs with eight Zen 5 cores each for a total of 128 cores and 256 threads in the box. The “scale out” Turins – akin to the “Bergamo” line parallel to standard Genoa parts – have only a dozen Zen 5c CCDs, but thanks to the removal of 2 MB of L2 cache per core and a reworking of the layout of the CCDs, there are sixteen cores per Zen 5c CCD compared to only eight for the Zen 5 CCDs. The Zen 5 and Zen 5c cores are laid out differently, but are functionally identical. This stands in stark contrast to Intel’s approach with Granite Rapids and Sierra Forest, which has a normal Xeon core called a P-core in the former and a very different, Atom-derived core called an E-core in the latter. How much this matters, the market will tell us.
As with prior Epyc CPU lines, AMD has created standard Turin parts that work in two-socket servers and then special versions, designated with a P, that are for single-socket servers and that have arbitrary and reasonable price cuts because they have their NUMA circuits crimped. There are F variants of the Turins aimed at high performance workloads (the F is for frequency enhanced), and we assume there will be X variants in the future – probably in Q1 2025 when Intel is making CPU announcements – that have extra L3 cache to boost performance for HPC and certain AI workloads that are cache sensitive.
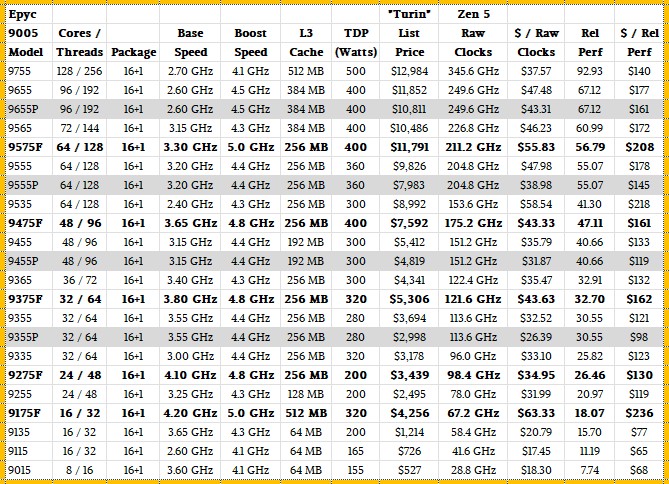
Without further ado, then, here are the Zen 5 SKUs of Turin so far:
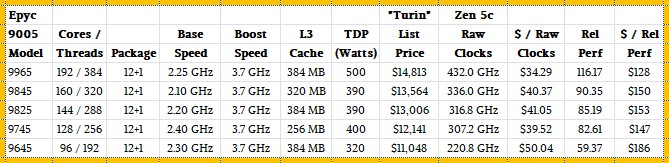
And here are the Zen 5c SKUs of Turin, with their higher core count, higher throughput, and more aggressive price/performance:
The progress that AMD has made compared to the 45 nanometer Shanghai Opterons launched in April 2009, smack dab in the middle of the Great Recession, is remarkable, and it bears pointing this out.
The Opteron 2387 was the reasonable, sort of middle bin part in the Shanghai line, which only had four SKUs. This chip had four Shanghai cores running at 2.8 GHz, with no boost speed on the clocks, and 6 MB of L3 cache, all in a tidy 75 watt thermal design point. It cost $873 a pop when bought in 1,000-unit trays that are standard in the server industry. (No, you don’t get a tray for $873. These ain’t potato chips. . . . )
To get relative performance, we multiply the clock speed of the chip times its core count times its cumulative IPC improvement compared to the Shanghai core.
The top bin Naples part, the Epyc 7601 with 32 cores running at 2.2 GHz, had 10.37X more performance and delivered it at $405 per unit of relative performance with its $4,200 price tag. With the penultimate bin Rome Epyc 7742, which was a more standard part than the Epyc 7H12 above it aimed at HPC workloads, the relative performance of this 64 core chip running at 2.25 GHz jumped to 24.40 and the cost per unit of performance dropped to $285. The penultimate bin 2.45 GHz 64-core Milan Epyc 7763 was rated at 31.61 – and was driven by microarchitecture and clock speed gains not core expansion – and price/performance inched down a bit to $250 per unit of performance. The penultimate 96-core Epyc 9654 running at 2.4 GHz was rated at 52.94 on our relative performance scale, and at $11,805 a pop that worked out to $223 per unit of performance.
The thing to note here is that it is easier to raise performance than it is to lower price/performance, and it is easier to raise performance by boosting core count than it is to do so with clock speed, thanks to thermal constraints.
With the jump to Turin, the currently top binned Epyc plain vanilla Epyc 9755 has 128 cores running at 2.7 GHz and it delivers a relative performance of 92.93 at a cost of $12,984. That works out to $140 per unit of performance, and so AMD has finally moved the needle here a lot when it comes to bang for the buck.
By the way, that is a 92.93X improvement in performance with a 14.9X increase in price and a 6.7X increase in power consumption compared to the touchstone Shanghai Opteron 2387, and a factor of 6.2X better bang for the buck over a little more than fifteen years.
The Zen 5c variants of Turin push the performance and value for dollar even harder. The Epyc 9965, which has 192 cores running at 2.25 GHz, have a relative performance of 116.17 and a price of $14,813, for a price/performance of $128 per unit of performance. That is 25 percent more peak theoretical integer throughput performance than the Epyc 9755 at 8.7 percent better bang for the buck.
Of course, you have to know how cache sensitive your workloads are before you choose a Zen 5c variant over a Zen 5 one. And you also have to look very carefully at the full SKU stacks to match a workload to a SKU. If high serial performance matters, you will pay a premium for that, as these tables show. There is also a premium you pay for higher throughput, but that is just a function of the yield on chiplets and is perfectly understandable and fair.
We are not going to get into the direct comparisons between AMD Turin 5 and Turin 5c and Intel Granite Rapids and Sierra Forest right here. But we think a relative comparison within the Intel line is illustrative right now.
First of all, and perhaps most importantly, the higher-cored Intel Sierra Forest parts have more cores, but significantly lower performance, lower prices, and better bang for the buck than the Granite Rapids chips. To be precise, the 144-core Xeon 6780E has 24 percent lower throughput than the 128-core Xeon 6980P, but bang for the buck improves by 16 percent for these top-bin parts. But as we pointed out above, the Turin 5c Epyc 9965 with 192 cores does 25 percent more work and costs 8.7 percent less per unit of work than the Turin 5 Epyc 9755 with 128 cores.
This is a big difference in strategy.
And second of all, let’s talk about relative performance gains for Intel over the same time between 2009 and 2024. For Intel Xeons, our touchstone server CPU from which we reckon relative performance is the 45 nanometer “Nehalem” Xeon E5540 from March 2009, also when the Great Recession was roaring. This is a four-core processor that runs at 2.53 GHz; it has 8 MB of L3 cache, burns 80 watts, and costs $744 a pop in 1,000-unit trays. Intel has increased its performance by 62X between the touchstone Xeon E5540 and the top bin Xeon 6 6980P, with power going up by 6.25X to 500 watts, price going up by 23.9X to $17,800, and price/performance improving by 2.6X. On just regular Turin parts, AMD has driven performance up by a factor of 92.93X, power up by 6.7X, price up by 14.9X, and price/performance has improved by 6.25X.
Stay tuned for the Turin architectural deep dive and the competitive analysis.


Sen. Weinberg: New Jersey must stop gambling with casino workers’ lives | Opinion

Strava 2024 Year in Sport: Social Fitness Is the No. 1 Trend | Well+Good

4 Ways To Use Employee Job Satisfaction To Drive 2025 Business Success

Final score predictions for Browns vs. Bengals in Week 16

Houston Texans schedule: Are the Texans playing today?

Maxx Crosby Adds His Unapologetic Style to Fashion Industry

Spain: World’s biggest lottery El Gordo awards billions – DW – 12/22/2024

Let’s talk business: Native Puebloan to head Springs Rescue Mission and more

Lose Weight and Gain Lean Muscle at the Same Time With This Effective Strategy
