Tech
Google offers its AI watermarking tech as free open source toolkit

Google also notes that this kind of watermarking works best when there is a lot of “entropy” in the LLM distribution, meaning multiple valid candidates for each token (e.g., “my favorite tropical fruit is [mango, lychee, papaya, durian]”). In situations where an LLM “almost always returns the exact same response to a given prompt”—such as basic factual questions or models tuned to a lower “temperature”—the watermark is less effective.
Google says SynthID builds on previous similar AI text watermarking tools by introducing what it calls a Tournament sampling approach. During the token-generation loop, this approach runs each potential candidate token through a multi-stage, bracket-style tournament, where each round is “judged” by a different randomized watermarking function. Only the final winner of this process makes it into the eventual output.
Can they tell it’s Folgers?
Changing the token selection process of an LLM with a randomized watermarking tool could obviously have a negative effect on the quality of the generated text. But in its paper, Google shows that SynthID can be “non-distortionary” on the level of either individual tokens or short sequences of text, depending on the specific settings used for the tournament algorithm. Other settings can increase the “distortion” introduced by the watermarking tool while at the same time increasing the detectability of the watermark, Google says.
To test how any potential watermark distortions might affect the perceived quality and utility of LLM outputs, Google routed “a random fraction” of Gemini queries through the SynthID system and compared them to unwatermarked counterparts. Across 20 million total responses, users gave 0.1 percent more “thumbs up” ratings and 0.2 percent fewer “thumbs down” ratings to the watermarked responses, showing barely any human-perceptible difference across a large set of real LLM interactions.
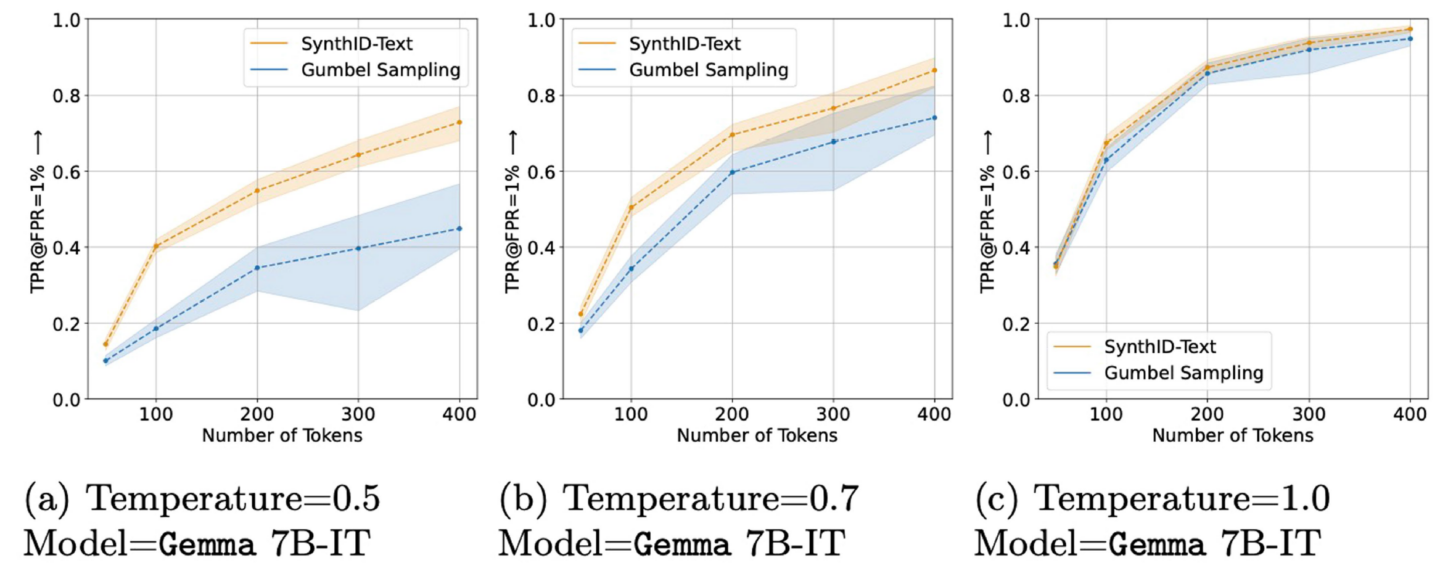
Google’s testing also showed its SynthID detection algorithm successfully detected AI-generated text significantly more often than previous watermarking schemes like Gumbel sampling. But the size of this improvement—and the total rate at which SynthID can successfully detect AI-generated text—depends heavily on the length of the text in question and the temperature setting of the model being used. SynthID was able to detect nearly 100 percent of 400-token-long AI-generated text samples from Gemma 7B-1T at a temperature of 1.0, for instance, compared to about 40 percent for 100-token samples from the same model at a 0.5 temperature.

Swiss business gets Christmas bonus from EU trade deal

Nissan, Honda announce plans to merge, creating world’s No. 3 automaker | CNN Business

Year of the Snake retreat in Hong Kong to feature snake-themed exercises

Liverpool news: Arne Slot ‘has brought a high level of consistency’

Honda and Nissan officially begin merger talks to create world’s third-largest automaker
Like it or not, Dallas Cowboys coach Mike McCarthy is gaining ground for a contract extension from Jerry Jones

Fitness influencer, 43, dead three months after he was shot during LA robbery

Second-hand fashion outpaces traditional retail in 2024: Survey

Bundesliga Team of the Week: Matchday 15
