Jobs
Methodology: Assessing the Likelihood of GenAI Replacing Work Skills – Indeed Hiring Lab

The Indeed Hiring Lab recently assessed the ability of GPT-4o, a GenAI model developed by OpenAI, to perform more than 2,800 job skills. We found that none of the more than 2,800 unique work skills are “very likely” to be replaced by generative artificial intelligence soon. Here’s a detailed description of what we did and the why behind some of the decisions we made for this analysis.
Data sources
This research utilized two data sources: Indeed’s rich skill database, and Indeed job posting data. Starting with Indeed’s universe of hundreds of millions of job postings, we identified more than 2,800 common work skills, from “account management” to “wound care.”
The second database we leveraged for this research is Indeed’s job posting data. Job postings are a timely indicator to measure the health of the labor market. For this research, we use US job posting data from August 01, 2023, to July 31, 2024, to capture recent trends in skill demands and evaluate the impact of GenAI technology on occupations.
Skills evaluation dimensions
Each skill was assessed across three main areas:
- The ability of GenAI to provide theoretical knowledge related to the skill.
- The ability of GenAI to solve problems using the skill.
- GenAI’s determination of the importance of physical presence in utilizing that skill.
Each of these three dimensions was scored on a 5-point scale, with a rating of 1 indicating very limited or no ability to apply a skill across that dimension, and a 5 indicating a strong ability.
These three ratings were considered by the model as part of an ultimate assessment of the likelihood that GenAI could replace a human in performing any of those 2,800+ individual skills. We used a similar scale rating, with 1 indicating that a skill is ‘very unlikely’ to be replaced and 5 indicating that a skill is ‘very likely’ to be replaced.
The table below shows the exact definitions of the three dimensions, the definition of the replacement potential, and the overall rating. The individual ratings scales from 1 to 5 are also displayed.
Leveraging Generative AI for this research
The detailed skill taxonomy and a short description of these skills were then used as part of a prompt utilizing OpenAI’s API and GPT-4o model (version gpt-4o-2024-05-13, the most advanced model publicly available at the time of the analysis) to ask the model to evaluate its own abilities to perform each of the 2,800+ skills, across three critical dimensions (more details below).
This analysis is the culmination of an intense, months-long, human/AI collaboration that resulted in a highly specific, more than 1,000-word prompt to ensure our digital colleague followed our human instructions to the letter. Engineering the prompt took many attempts to get right — the more complex the ask is of GenAI, the more complex and detailed the prompt needs to be. All findings were validated by human researchers, and if the results did not meet expectations, the prompt was adjusted accordingly.
Our final prompt was structured in seven sections and followed common prompt engineering strategies. The seven sections were organized as follows:
- Provides clear instructions on what the model can expect and detailed context surrounding the input data.
- Provides background and purpose of this request.
- Describes the intended audience for the results, to allow the model to adopt the required depth and expert level.
- Provides step-by-step instructions that are concrete and clear on the tasks. A step-by-step approach provides the best guidance and strategy.
- Asks the model to start with a “thinking” process. Giving the model time to “think” is crucial and essential for improving results.
- Evaluates the model’s performance on three dimensions, providing a concrete definition for all three dimensions, and also for the overall assessment of the likelihood of replacing a human being in performing the skill.
- We asked the model to justify its ratings. Justification is a strength of the latest GPT models and is a very important step for human validation in order to understand and evaluate the decision behind a rating. With this step, we increased the transparency of the model’s decisions. Another advantage of this step is that we can use those justifications when communicating the results.
Prompt engineering is a science and a very iterative process. Our human validation and subsequent fine-tuning included reviewing the ratings, the distribution of ratings, and the justifications of the ratings, to ensure they were reflective of real-world skill requirements.
The different dimensions upon which we rated GenAI’s abilities are all related. Taken together they provide a more nuanced evaluation of GenAI’s impact on skills and the labor market. One challenge we had to overcome was the strong correlation between the two dimensions of physical execution and problem-solving ability. We defined the problem-solving ability as, “The model’s ability to apply theoretical knowledge to solve problems or provide practical solutions.” But even for skills that require hands-on execution (and are, almost by definition, less likely to be replaced by GenAI tools that lack bodies or appendages to do manual work), theoretical knowledge might be helpful. To take this into account, we added further instructions on the definition as follows: “If problem-solving can be separated from physical execution, rate this dimension independently; otherwise, include physical aspects in the rating.”
We’ve also evaluated the model’s performance and accuracy by comparing results across different models. We compared a sample of skills (to allow human validation) across GPT-4o (the model we used for this research) and GPT-4-turbo. The results generated by GPT-4o were determined to be more reliable.
When utilizing the GPT-4o model, we had the option of running the prompt at various “temperature” settings, which control the randomness of the model’s responses. Lower temperatures, such as 0, produce more deterministic and consistent outputs, while higher temperatures introduce more variability and creativity in the results. We experimented with different temperatures and compared the outcomes across settings of 0, 0.3, and 0.7. To ensure reproducibility we chose to use a temperature setting of 0.
The final GenAI skill rating
Each of the 2,800+ skills was assessed 15 times to increase the reliability and robustness of the results. We consolidated all 15 runs into one final rating. For each dimension — theory, physical execution, problem-solving ability, and replacement potential — the mode is calculated as the most frequently occurring rating across 15 runs. In the event of a tie, where multiple ratings share the same highest frequency, the lower value was selected.
The justification was always selected from the first run within the group of ratings that share the mode (the most frequently occurring rating). Before finalizing this approach, we performed a spot check to compare the justifications across runs and confirmed that they were sufficiently similar. The distribution of ratings was very consistent across all 15 runs.
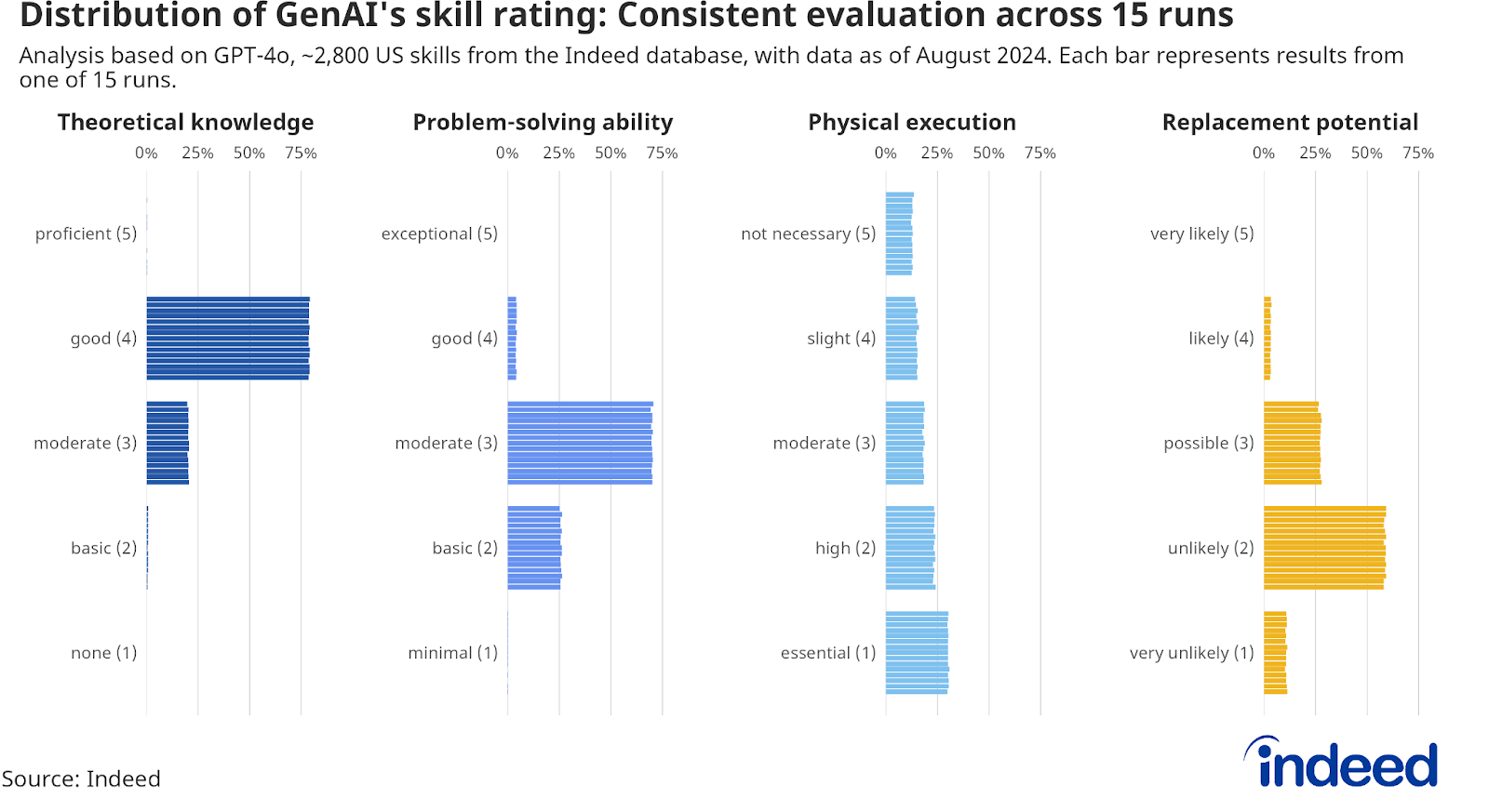
At the skill level, the variation across runs differs depending on the dimension. The rating of theoretical knowledge showed the highest consistency across runs. For 80.7% of skills, the theoretical knowledge rating was consistent across all 15 runs. For 73.7% of skills, the problem-solving rating was consistent across all 15 runs. The physical rating showed more variance: For 40.9% of skills, the physician execution rating was consistent across all 15 runs. The overall rating of the replacement potential was for 48.9% of skills consistent across all 15 runs.
The range of differences was only 1 in most of the cases where there was a difference for theoretical knowledge (99.3%), problem-solving (99.9 %), or replacement potential (98.5 %). The physical execution rating showed more variation across runs. For 70.6% of skills with variation across runs, the range was only 1. For 23.4% the range was 2. 5.4% of skills had a range of 3. And there are 9 skills with a range of 4. Our approach to using the mode made sure that these outliers were moderated and didn’t bias our results.
Across all 15 runs, “data entry” (defined as “experience or skill entering data into a database or computer software”) was the only skill rated as “very likely” to be replaced by GenAI, and that happened in only one of the runs. In all the other 14 runs, this skill was rated as ‘likely (4)’ to be replaced. With the consolidation of all 15 runs, the final rating had no skill rated as ‘very likely’ to be replaced. This result proves the robustness of our approach in using 15 runs and consolidating them. This reduces outliers and increases the reliability and robustness of the results.
Skills that are likely to be replaced
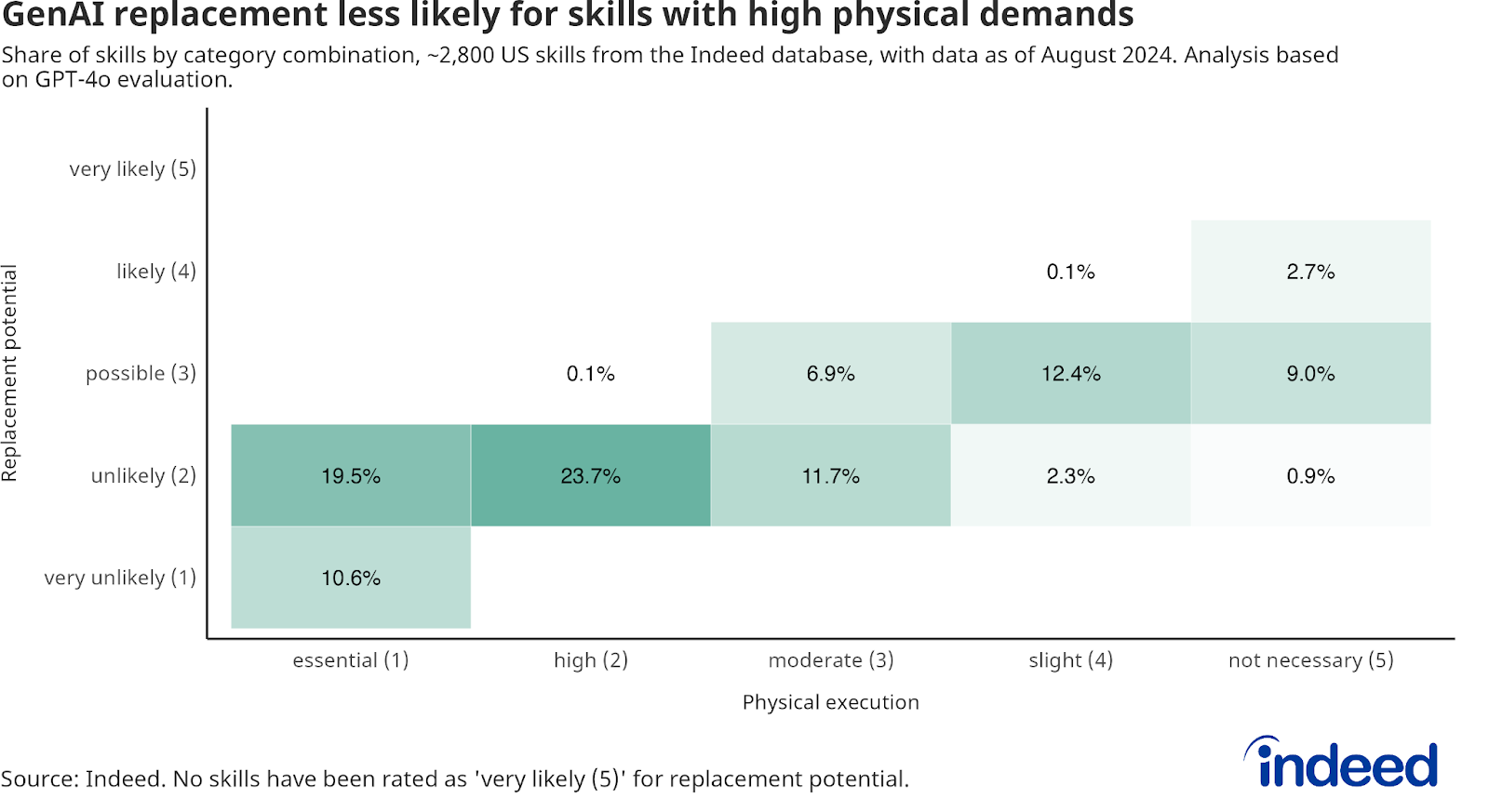
The majority of skills (53.8%) require ‘essential (1)’ or ‘high (2)’ physical execution and are therefore ‘very unlikely (1)’ or ‘unlikely (2)’ to be replaced by GenAI. Only 2.8% of skills require no or little physical execution and are at the same time ‘likely (4)’ to be replaced.
Impact on jobs
Eighty skills reached the ‘likely’ rating on the final replacement assessment. They are all characterized by ‘good (4)’ problem-solving abilities — there are no skills with ‘exceptional (5)’ problem-solving abilities — and the theoretical knowledge of GenAI is either ‘good (4)’ or even ‘proficient (5)’. Only four skills were given the highest rating by the model on their ability to provide theoretical knowledge — “generative AI” “grammar” “text classification” and “writing skills.” It makes sense that a generative AI tool would be proficient with Generative AI skills, and that the large language models (LLMs) that underpin these tools would have a strong theoretical backing in language and writing.

Frank Sinatra fans celebrate 109 years since the iconic crooner was born at party in Grasmere dining spot | Inside Out

U.S. Continues To Dominate In World Cup Men’s Freeski Halfpipe

See the latest class of individuals joining the Greater Lansing Sports Hall of Fame

Luminous Pluck: The Story of a World War II Heroine

How Unequal Pay And Unpredictable Earnings Cause Stress For Women In Sports
The best unconventional Christmas movies as shared by Yahoo readers

Jameis Winston inactive, David Njoku active for Browns on Sunday

Apple might be working on a smart doorbell | TechCrunch

Eagles inactives: Sydney Brown will play vs. Commanders
